2020年7月17日下午15:00-17:00,应俄罗斯语言文学与文化研究中心邀请,中国科学院自动化研究所研究员、博士生导师宗成庆在腾讯会议平台作了题为《基于网络大数据的语言资源建设》在线学术讲座,来自国内各高校的专家、学生约130人参加此次线上学术报告。报告由黑龙江省“头雁”团队首席专家易绵竹教授主持。
宗成庆研究员认为语言资源建设与其他领域的国家基础资源建设同样重要,面向特定目标和任务的语言资源建设是研发高质量NLP系统的重要基础和条件。报告首先以基于网络大数据的语言资源建设为目标,在简要介绍机器翻译方法的基础上,详细介绍了基于网络内容的双语平行语料自动获取方法,最后提出如下建议:第一、建立统一的标注规范和标准;第二、构建大规模、高质量国家级基础语料库;第三、面向特定目标和任务构建高质量专用语料库;第四、研发高水平自动标注工具,建设开放标注平台;第五、制定合理的语料共享机制。  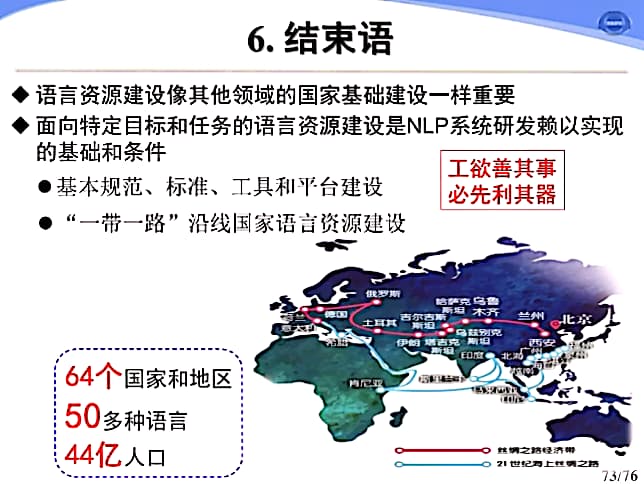
讲座结束后,宗成庆教授与在线师生进行了连线互动,并对翻译回译文本与原文本的情感值的稳定差异、多模态语料的标注标准等相关问题进行了逐一解答。整场讲座资料详实、视野开阔、发人思考。
宗成庆,中国科学院自动化研究所研究员、博士生导师,中国科学院大学岗位教授,享受国务院特殊津贴。主要从事自然语言处理和机器翻译等研究,主持国家项目10余项,目前担任国家重点研发计划重点专项首席科学家,发表论文200余篇,出版《统计自然语言处理》和《文本数据挖掘》两部专著及一部译著。2013年当选国际计算语言学委员会(ICCL)委员,现为亚洲自然语言处理学会(AFNLP)主席、中国中文信息学会副理事长,中国人工智能学会会士,学术期刊ACM TALLIP副主编、《自动化学报》副主编,是国际学术会议ACL-IJCNLP’2015、COLING’2020的程序委员会主席和ACL-IJCNLP’2021大会主席,曾4次担任国际人工智能领域顶级学术会议AAAI和IJCAI的领域主席。曾获国家科技进步奖二等奖、中国中文信息学会“钱伟长中文信息处理科学技术奖”一等奖等,荣获北京市优秀教师、中科院优秀导师、宝钢优秀教师等荣誉。 | 


 位置:
位置: